Azure Machine Learning Study notes
Setting up storage for Azure ML
Create storage account
az storage account create \
--name mldemoblob8765 \
--resource-group mldemo \
--location westus \
--sku Standard_LRS \
--kind StorageV2
Create container in the storage account
az storage container create \
--name mlfiles \
--account-name mldemoblob8765
Creating a datastore in Azure ML
Create a permanent connection to a container in a storage account and define it as one of our datastores in the Azure Machine Learning workspace.
$schema: https://azuremlschemas.azureedge.net/latest/azureBlob.schema.json
name: mldemoblob
type: azure_blob
description: main ML blob storage
account_name: mldemoblob8765
container_name: mlfiles
credentials:
sas_token: <your_token>
Creating Datasets
A Dataset object can be accessed or passed around in the current environment through its object reference. However, a dataset can also be registered (and versioned), and hence accessed through the dataset name (and version) – this is called a registered dataset.
from azureml.core import Dataset
path = 'https://...windows.net/demo/Titanic.csv'
ds = Dataset.Tabular.from_delimited_files(path)
Once we have a reference to a datastore, we can access data within it. In the following example, we create a file dataset from files stored in a directory of the mldata datastore:
from azureml.core import Dataset, Datastore
datastore_name = "mldata"
datastore = Datastore.get(ws, datastore_name)
ds = Dataset.File.from_files((datastore, "cifar10/"))
Registering datasets
ds = ds.register(ws, name="titanic",
create_new_version=True)
# exploring it:
ds = Dataset.get_by_name(ws, name="titanic", version=1)
panads_df = ds.to_pandas_dataframe()
pandas_df.head()
Passing external data as URL
import pandas as pd
path ='https://...windows.net/demo/Titanic.csv'
df = pd.read_csv(path)
print(df.head())
Our goal is to pass the data from the authoring script to the training script, so it can be tracked and updated easily in the future. To achieve this, we can’t send the DataFrame directly, but have to pass the URL to the CSV file and use the same method to fetch the data in the training script. Let’s write a small training script whose only job is to parse the command-line arguments and fetch the data from the URL:
import argparse
import pandas as pd
parser = argparse.ArgumentParser()
parser.add_argument("--input", type=str)
args = parser.parse_args()
df = pd.read_csv(args.input)
print(df.head())
As we see in the preceding code, we pass the data path from the command-line –input argument and then load the data from the location using pandas’ read_csv().
Next, we create a ScriptRunConfig constructor to submit an experiment run to Azure Machine Learning that executes the training script
src = ScriptRunConfig(
source_directory="code",
script='access_data_from_path.py',
arguments=['--input', path],
environment=get_current_env())
Problems with above approach:
- We can’t pass the pandas DataFrame or a DataFrame identifier to the training script; we have to pass the data through the URL to its location. If the file path changes, we have to update the argument for the training script.
- The training script doesn’t know that the input path refers to the input data for the training script, it’s simply a string argument to the training script. While we can track the argument in Azure Machine Learning, we can’t automatically track the data.
Passing external data as a direct dataset
from azureml.core import Dataset
path ='https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
ds = Dataset.Tabular.from_delimited_files(path)
print(ds.to_pandas_dataframe().head())
## and we can use it like this in training script:
import argparse
from azureml.core import Dataset, Run
parser = argparse.ArgumentParser()
parser.add_argument("--input", type=str)
args = parser.parse_args()
run = Run.get_context()
ws = run.experiment.workspace
ds = Dataset.get_by_id(ws, id=args.input) # Keyline!! notice get_by_id
print(ds.to_pandas_dataframe().head())
Next, we write a run configuration to submit the preceding code as an experiment to Azure Machine Learning. First, we need to convert the dataset into a command-line argument and pass it to the training script so it can be automatically retrieved in the execution runtime. We can achieve this by using the as_named_input(name) method on the dataset instance, which will convert the dataset into a named DatasetConsumptionConfig argument that allows the dataset to be passed to other environments.
In this case, the dataset will be passed in direct mode and provided as the name environment variable in the runtime environment or as the dataset ID in the command-line arguments. The dataset will also get tracked in Azure Machine Learning as an input argument to the training script.
However, as we saw in the previous code snippet, we use the Dataset.get_by_id() method to retrieve the dataset in the training script from the dataset ID. We don’t need to manually create or access the dataset ID, because the DatasetConsumptionConfig argument will be automatically expanded into the dataset ID when the training script is called by Azure Machine Learning with a direct dataset:
src = ScriptRunConfig(
source_directory="code",
script='access_data_from_dataset.py',
arguments=['--input', ds.as_named_input('titanic')],
environment=get_current_env())
Newer version for sdk v2 !!!
env = Environment('my_env')
packages = CondaDependencies.create(conda_packages=['pip'],
pip_packages=['azureml-defaults',
'azureml-dataprep[pandas]'])
env.python.conda_dependencies = packages
script_config = ScriptRunConfig(source_directory='my_dir',
script='script.py',
arguments=['--ds', tab_ds],
environment=env)
# And the script
from azureml.core import Run, Dataset
parser.add_argument('--ds', type=str, dest='dataset_id')
args = parser.parse_args()
run = Run.get_context()
ws = run.experiment.workspace
dataset = Dataset.get_by_id(ws, id=args.dataset_id)
data = dataset.to_pandas_dataframe()
env = Environment('my_env')
packages = CondaDependencies.create(conda_packages=['pip'],
pip_packages=['azureml-defaults',
'azureml-dataprep[pandas]'])
env.python.conda_dependencies = packages
script_config = ScriptRunConfig(source_directory='my_dir',
script='script.py',
arguments=['--ds', tab_ds.as_named_input('my_dataset')],
environment=env)
# Script
from azureml.core import Run
parser.add_argument('--ds', type=str, dest='ds_id')
args = parser.parse_args()
run = Run.get_context()
dataset = run.input_datasets['my_dataset']
data = dataset.to_pandas_dataframe()
Accessing data during training
While external public data reachable through a URL is created and passed as a direct dataset, all other datasets can be accessed either as a download or as a mount. For big data datasets, Azure Machine Learning also provides an option to mount a dataset as a Hadoop Distributed File System (HDFS).
Python SDK 2 side track
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Get a handle to the workspace. You can find the info on the workspace tab on ml.azure.com
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>", # this will look like xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Azure Cli2
https://learn.microsoft.com/en-us/training/paths/train-models-azure-machine-learning-cli-v2/
pipeline tutorial
https://learn.microsoft.com/en-us/azure/machine-learning/tutorial-pipeline-python-sdk
First you always get the “credential”:
credential = InteractiveBrowserCredential()
and then a MLClient object
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Azure Machine Learning uses a Data object to register a reusable definition of data, and consume data within a pipeline. In the section below, you’ll consume some data from web url as one example. Data from other sources can be created as well. Data assets from other sources can be created as well.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
web_path = "https://archive.ics.uci.edu/ml/machine-learning-databases/00350/default%20of%20credit%20card%20clients.xls"
credit_data = Data(
name="creditcard_defaults",
path=web_path,
type=AssetTypes.URI_FILE,
description="Dataset for credit card defaults",
tags={"source_type": "web", "source": "UCI ML Repo"},
version="1.0.0",
)
This code just created a Data asset, ready to be consumed as an input by the pipeline that you’ll define in the next sections. In addition, you can register the data to your workspace so it becomes reusable across pipelines.
Registering the data asset will enable you to:
- Reuse and share the data asset in future pipelines
- Use versions to track the modification to the data asset
- Use the data asset from Azure Machine Learning designer, which is Azure Machine Learning’s GUI for pipeline authoring
Since this is the first time that you’re making a call to the workspace, you may be asked to authenticate. Once the authentication is complete, you’ll then see the dataset registration completion message.
credit_data = ml_client.data.create_or_update(credit_data)
print(
f"Dataset with name {credit_data.name} was registered to workspace, the dataset version is {credit_data.version}"
)
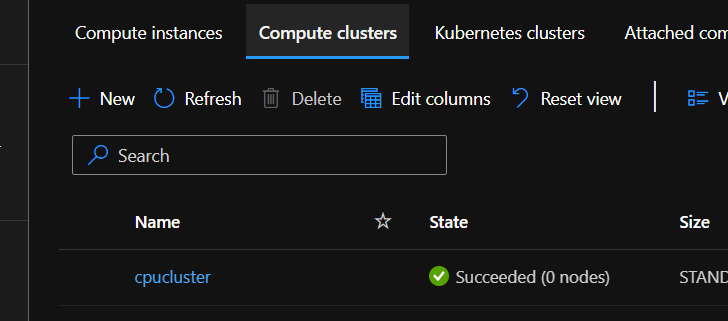
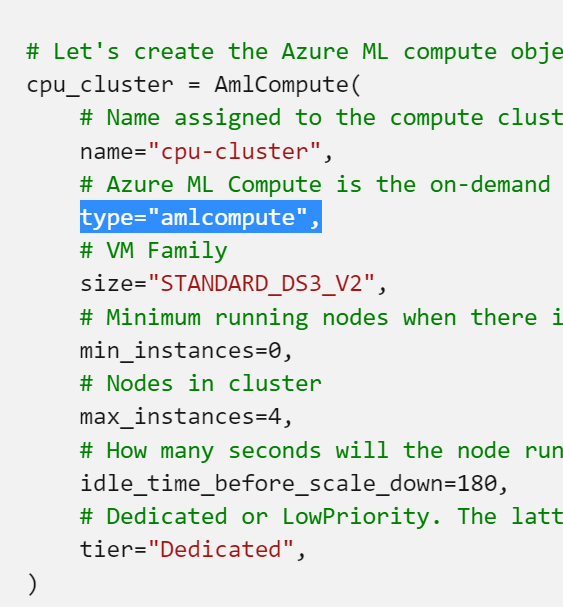
using type amlcompute creates a compute cluster while the other is “computeinstance”
create environment for the pipeline steps:
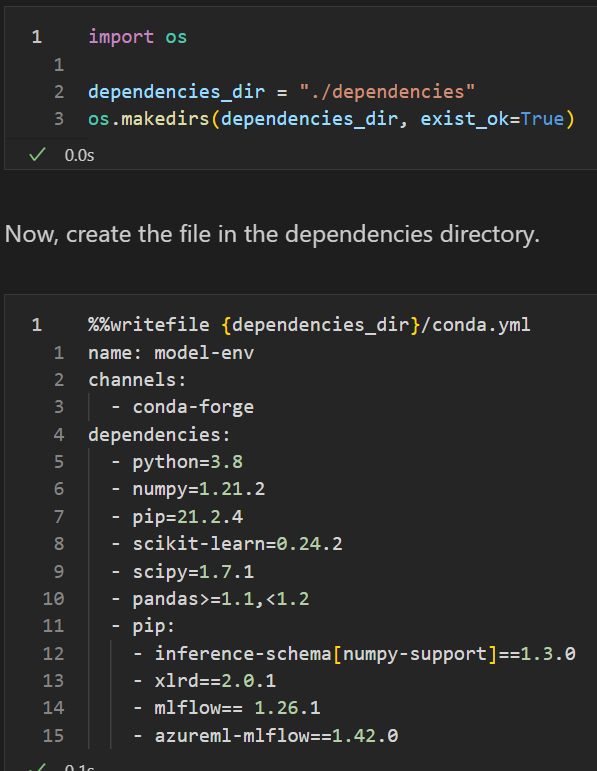
it can be used to create custom envs:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
version="0.1.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)