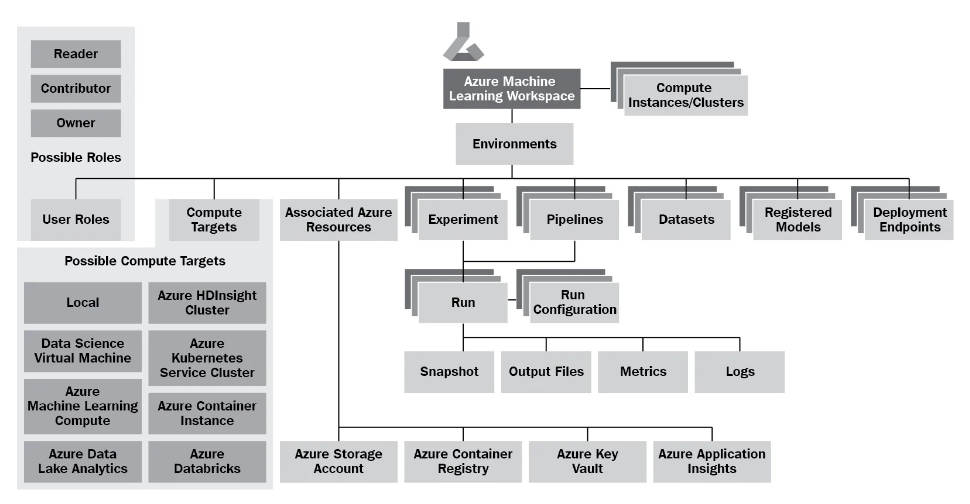
to keep track of the iterations of our model training, we define them as runs and align them to a construct called an experiment, which collects all information concerning a specific model we want to train. To do this, we will connect any training script run we perform to a specific experiment.
s described before, a run is a single execution of your experiment (your training script), with different settings, models, code, and data but the same comparable metric. You use runs to test multiple hypotheses for a given experiment and track all the results within the same experiments.
Typically, we can create a run object and start logging this run here by invoking the following function:
# Create and start an interactive run
run = exp.start_logging(snapshot_directory='.')
The preceding code not only creates and initializes a new run; it also takes a snapshot of the current environment, defined through the snapshot_directory argument, and uploads it to the Azure Machine Learning workspace. To disable this feature, you need to explicitly pass snapshot_directory=None to the start_logging() function.
In this case, the snapshot will take every file and folder existing in the current directory. To restrict this, we can specify the files and folders to ignore using a .amlignore file.
This is because it is good practice to wrap your training code in a try and except block in order to propagate the status of your run in Azure. If the training run fails, then the run will be reported as a failed run in Azure. You can achieve this by using the following code snippet:
run = exp.start_logging(snapshot_directory='.')
try:
# train your model here
run.complete()
except:
run.cancel()
raise
or you can simplify it to this:
with exp.start_logging(snapshot_directory='.') as run:
# train your model here
pass
Besides the snapshot directory, which is uploaded before the run starts, we also end up with two additional directories after the run created by the ML script, namely outputs and logs.
Once a run is completed using run.complete(), all content of the outputs directory is automatically uploaded to the Azure Machine Learning workspace. In our simple example using Keras, we can use a checkpoint callback to only store the best model of all epochs to the outputs directory, which then is tracked with our run.
As a final step, we want to register our best model, which we have stored in the output folder, to the model registry in the Azure Machine Learning workspace.
# Upload the best model
run.upload_file(model_name, model_path)
# Register the best model
run.register_model(model_name, model_path=model_name,
model_framework='TfKeras')
A Keras callback from validation metrics
The goal is to evaluate the model created in each epoch against the validation dataset to get the validation metrics for each epoch. We already used an existing callback to check for the best model in each epoch, so it might be a good idea to write one ourselves to track the metrics in each epoch.
from tensorflow.keras.callbacks import Callback
import numpy as np
class AzureMlKerasCallback(Callback):
def __init__(self, run):
super(AzureMlKerasCallback, self).__init__()
self.run = run
# Keras calls this at the end of an epoch
def on_epoch_end(self, epoch, logs=None):
# logs is filled by Keras in the following format at the end of an epoch
# {loss:'0.1233', accuracy: '0.5945', val_loss:'0.5354', val_accuracy:'0.2344'}
# the metrics here: loss defined by default, accuracy defined by the model.compile() function
# loss, accuracy is evaluated with the training data set
# val_loss, val_accuracy is evaluated with the validation set (defined in the model.fit() function)
logs = logs or {}
# add tracked metrics to the run logging
for metric_name, metric_val in logs.items():
if isinstance(metric_val, (np.ndarray, np.generic)):
self.run.log_list(metric_name, metric_val.tolist())
else:
self.run.log(metric_name, metric_val)
Enhancing the registration of models
Now that we have metrics to read out and work with, we can, as a final step, enhance the way we save the best model to the model registry.
So far, we always update the model with a new version as soon as a new model is available. However, this doesn’t automatically mean that the new model has a better performance than the last model we registered in the workspace. As we want a new version of the model to actually be better than the last version, we need to check for that.
Therefore, a common approach is to register the new model only if the specified metric is better than the highest previously stored metric for the experiment. Let’s implement this functionality.
We can define a function that returns a generator of metrics from an experiment, like this:
from azureml.core import Run
def get_metrics_from_exp(exp, metric, status='Completed'):
for run in Run.list(exp, status=status):
yield run.get_metrics().get(metric)
The preceding generator function yields the specified tracked metric for each run that is completed. We can use this function to return the best metric from all previous experiment runs to compare the evaluated score from the current model and decide whether we should register a new version of the model. We should do this only if the current model performs better than the previous recorded model. For that, we need to compare a metric. Using the test accuracy is a good idea, as it is the model tested against unknown data:
# get the highest test accuracy
best_test_acc = max(get_metrics_from_exp(
exp,'Test accuracy')
default = 0)
# upload the model
run.upload_file(model_name, model_path)
if scores[1] > best_test_acc:
# register the best model as a new version
run.register_model(model_name, model_path=model_name)
Scheduling the script execution
Let’s implement this in a so-called authoring script. We call it an authoring script (or authoring environment) when the script or environment’s job is to schedule another training or experimentation script. In addition, we will now refer to the script that runs and executes the training as the execution script (or execution environment).
We need to define two things in the authoring script – an environment we will run on and a run configuration, to which we will hand over the execution script, the environment, and a possible compute target.
First, we need to define an environment. As we are still running locally, we create an environment with user-managed dependencies called user-managed-env. This will just take our environment as is from our local machine:
from azureml.core.environment import Environment
myenv = Environment(name = "user-managed-env")
myenv.python.user_managed_dependencies = True
In the next block, we define the location and name of the execution script
import os
script = 'cifar10_cnn_remote.py'
script_folder = os.path.join(os.getcwd(), 'code')
Finally, we define a run configuration using a ScriptRunConfig object and attach to it the source directory, the script name, and our previously defined local environment:
from azureml.core import ScriptRunConfig
runconfig = ScriptRunConfig(source_directory=script_folder,
script=script,
environment = myenv)
run = exp.submit(runconfig)
run.wait_for_completion(show_output=True)
Finally, let’s have a look at the execution script we are using. Open the file named cifar10_cnn_remote.py in the code directory. Scanning through this, you should find two additional parts that we added to the original model training code.
The first one is the part where we write debug logs into the logs folder:
# log output of the script
logging.basicConfig(filename='logs/debug.log',
filemode='w',
level=logging.DEBUG)
logger_cb = CSVLogger('logs/training.log')
the second looks like this:
from azureml.core import Run
# load the current run
run = Run.get_context()
The reason for this call is that when we want to move to a remote execution environment, we need to infer the run context. Therefore, we need to load the run object from the current execution context instead of creating a new run, as shown in the previous sections, where we used the exp.start_logging() call.
The run object will be automatically linked with the experiment when it was scheduled through the authoring script. This is handy for remote execution, as we don’t need to explicitly specify the run object in the execution script anymore. Using this inferred run object, we can log values, upload files and folders, and register models exactly as in the previous sections.