MLFlow pipelines
I’m going through the MLFlow pipeline presentation to see if they are useful/replacement for Azure ML pipelines.
TFX good but too hard:

Maven good in java ecosystem:

Maven might not be good for ML as such:

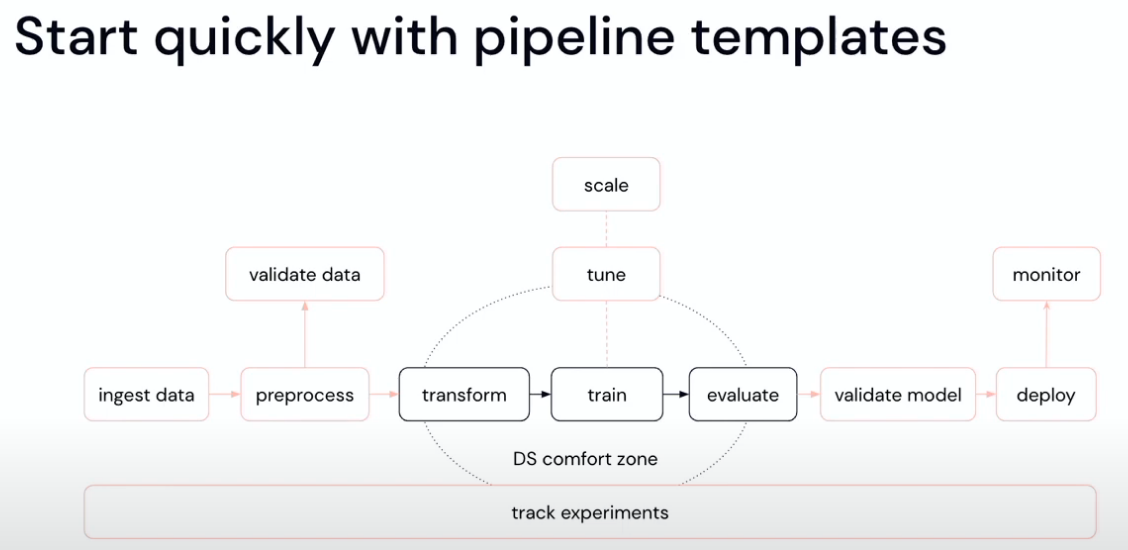
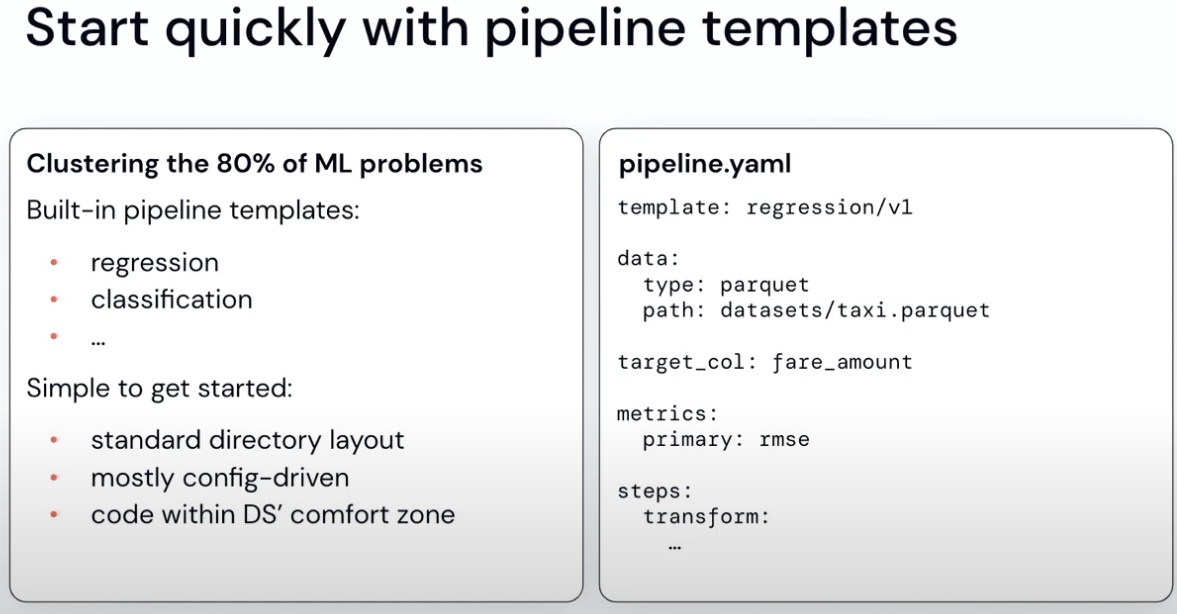


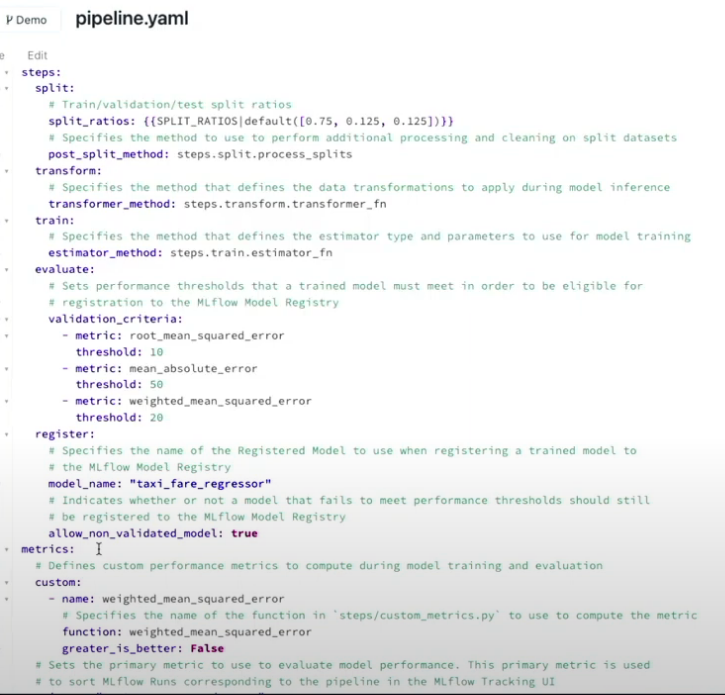
Looks bit too constrained but will try it out later:
Now moving to other topics. First off, deep dive to TSDB.
TimescaleDB Continuous Aggregates
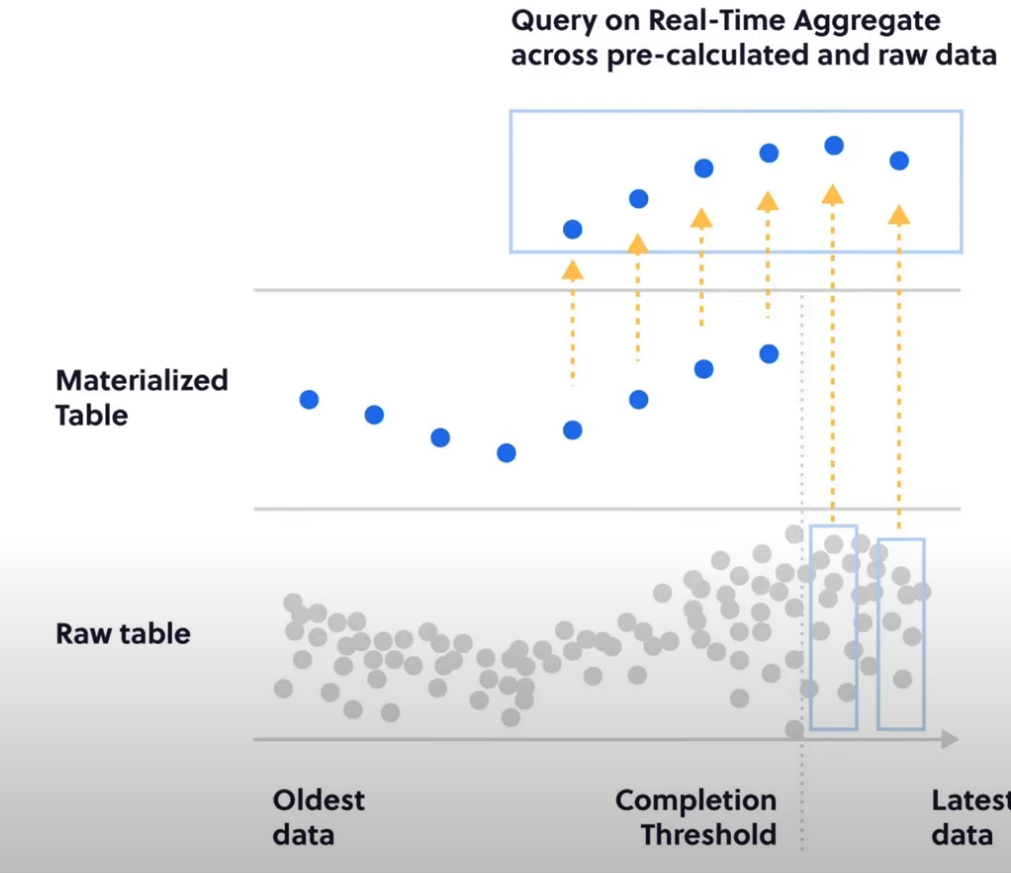
Basic time scale usage
select all stock data from the last day:
SELECT * FROM stocks_real_time srt
WHERE time > now() - INTERVAL '1 day';
Combine table and hypertable: calculate average Apple price for last two days
SELECT
avg(price)
FROM stocks_real_time srt
JOIN company c ON c.symbol = srt.symbol
WHERE c.name = 'Apple' AND time > now() - INTERVAL '2 days';
Real power of timeseries db: buckets
SELECT
time_bucket('1 day', time) AS bucket,
symbol,
avg(price)
FROM stocks_real_time srt
WHERE time > now() - INTERVAL '1 week'
GROUP BY bucket, symbol
ORDER BY bucket, symbol;
Enough of the video course, now to real tutorial
https://docs.timescale.com/timescaledb/latest/tutorials/time-series-forecast/
Found something really useful: Pgcopy
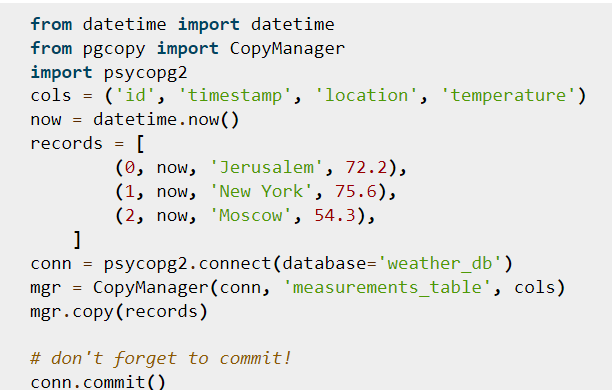
https://pgcopy.readthedocs.io/en/latest/
for data without time column I could maybe use this:
https://pandas.pydata.org/docs/reference/api/pandas.date_range.html
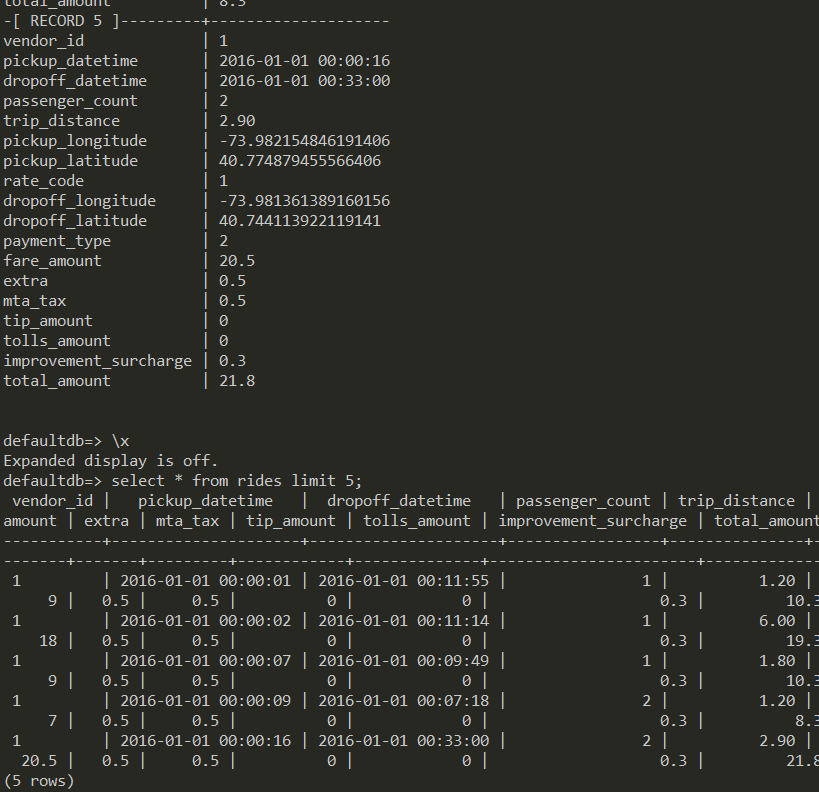
small detail in psql: the \x toggle
ZomboDB extension for text queries
