Reading the packt book about MLflow
Adding MLflow to code
import mlflow
from sklearn.linear_model import LogisticRegression
mlflow.sklearn.autolog()
with mlflow.start_run():
clf = LogisticRegression()
clf.fit(X_train, y_train)
the mlflow.sklearn.autolog() instruction enables you to automatically log the experiment in the local directory.
Exploring MLflow projects
An MLflow project represents the basic unit of organization of ML projects. There are three different environments supported by MLflow projects: the Conda environment, Docker, and the local system.
MLflow in docker container
name: syspred
docker_env:
image: stockpred-docker
entry_points:
main:
command: "python mljob.py"
{kind=link}
MLflow Tracking
The MLflow tracking component is responsible for observability. The main features of this module are the logging of metrics, artifacts, and parameters of an MLflow execution. It provides vizualisations and artifact management features.
In a production setting, it is used as a centralized tracking server implemented in Python that can be shared by a group of ML practitioners in an organization. This enables improvements in ML models to be shared within the organization.
MLflow Models
MLflow Models is the core component that handles the different model flavors that are supported in MLflow and intermediates the deployment into different execution environments.
Internally, MLflow sklearn models are persisted with the conda files with their dependencies at the moment of being run and a pickled model as logged by the source code:
artifact_path: model_random_forest
flavors:
python_function:
env: conda.yaml
loader_module: mlflow.sklearn
model_path: model.pkl
python_version: 3.7.6
sklearn:
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 0.23.2
run_id: 22c91480dc2641b88131c50209073113
utc_time_created: '2020-10-15 20:16:26.619071'
~
The MLflow Models component allows the creation of custom-made Python modules that will have the same benefits as the built-in models, as long as a prediction interface is followed.
MLflow Registry
The model registry component in MLflow gives the ML developer an abstraction for model life cycle management. It is a centralized store for an organization or function that allows models in the organization to be shared, created, and archived collaboratively.
Chapter 2
1. Implement the heuristic model in MLflow
In the following block of code, we create the RandomPredictor class, a bespoke predictor that descends from the mlflow.pyfunc.PythonModel class. The main predict method returns a random number between 0 and 1:
import mlflow
class RandomPredictor(mlflow.pyfunc.PythonModel):
def __init__(self):
pass
def predict(self, context, model_input):
return model_input.apply(lambda column: random.randint(0,1))
2. Save the model in MLflow
The following block of code saves the model with the name random_model in a way that can be retrieved later on. It registers within the MLflow registry in the local filesystem:
model_path = "random_model"
baseline_model = RandomPredictor()
mlflow.pyfunc.save_model(path=model_path, python_model=random_model)
3. run your mlflow job
mlflow run .
4. Start serving api
mlflow models serve -m ./mlruns/0/b9ee36e80a934cef9cac3a0513db515c/artifacts/random_model/
Chapter 3
=======
Data science workbench setup
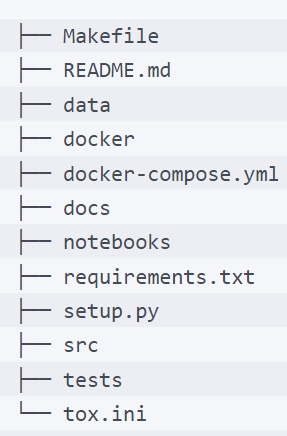
- Makefile: This allows control of your workbench. By issuing commands, you can ask your workbench to set up a new environment notebook to start MLflow in different formats.
- README.md: A file that contains a sample description of your project and how to run it. data folder: A folder where we store the datasets used during development and mount the data directories of the database when running locally.
- docker: A folder that encloses the Docker images of the different subsystems that our environment consists of.
- docker-compose.yml: A file that contains the orchestration of different services in our workbench environment—namely: Jupyter Notebooks, MLflow, and PostgreSQL to back MLflow.
- docs: Contains relevant project documentation that we want persisted for the project.
- notebooks: A folder that contains the notebook information.
- requirements.txt: A requirements file to add libraries to the project.
- src: A folder that encloses the source code of the project, to be updated in further phases of the project.
- tests: A folder that contains end-to-end testing for the code of the project.
- tox.ini: A templated file that controls the execution of unit tests.
Rest of the chapter is just examples running different ml models on simple data.
Chapter 5 Managing Models
There are two main components to manage models:
- Models: This module manages the format, library, and standards enforcement module on the platform. It supports a variety of the most used machine learning models: sklearn, XGBoost, TensorFlow, H20, fastai, and others. It has features to manage output and input schemas of models and to facilitate deployment.
- Model Registry: This module handles a model life cycle, from registering and tagging model metadata so it can be retrieved by relevant systems. It supports models in different states, for instance, live development, testing, and production.
An MLflow model is at its core a packaging format for models. The main goal of MLflow model packaging is to decouple the model type from the environment that executes the model. A good analogy of an MLflow model is that it’s a bit like a Dockerfile for a model, where you describe metadata of the model, and deployment tools upstream are able to interact with the model based on the specification.

Models are defined with a mlflow models file:
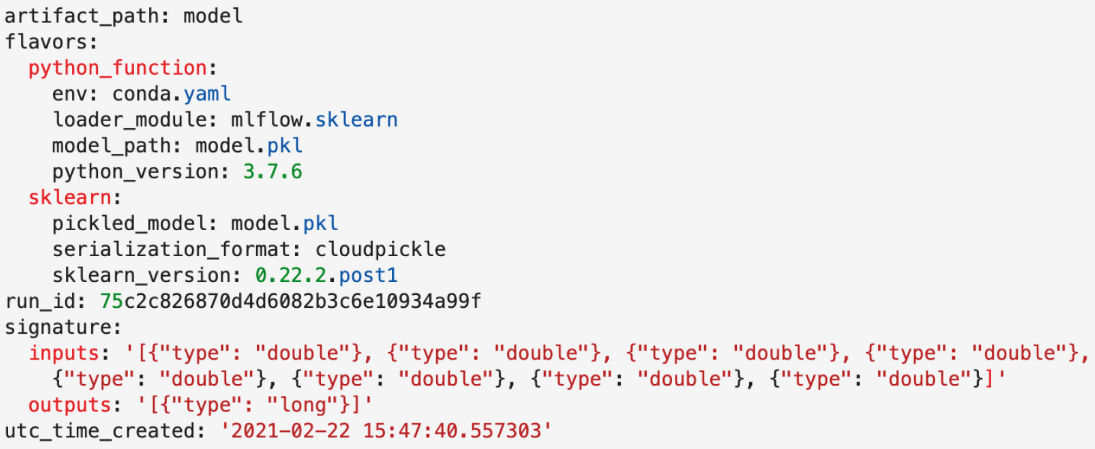
Model signatures and schemas
An important feature of MLflow is to provide an abstraction for input and output schemas of models and the ability to validate model data during prediction and training.
MLflow throws an error if your input does not match the schema and signature of the model during prediction.
The MLmodel file contains the signature in JSON of input and output files. For some of the flavors autologged, we will not be able to infer the signature automatically so you can provide the signature inline when logging the model:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name=’untuned_random_forest’):
…
signature = infer_signature(X_train,
wrappedModel.predict(None, X_train))
mlflow.pyfunc.log_model(“random_forest_model”,
python_model=wrappedModel,
signature=signature)
Rest of the chapter describes the Model registry. Nothing too new there for me.