Introduction
I’ve been planning for a while to make a project that combines as many of the new hype technologies as I can into one track. I’ll base it around the Serverless ML course from Hopsworks and also try to integrate other technologies such as Dagster, MLFlow, DuckDB and so on.
The idea is to use the sort of ideas presented in the course for credit card fraud detection, but transform it into stress detection.
In the beginning…
One thing I’m still figuring out is the optimal project folder structure, but the best I’ve come so far is the
which is trivially easy to use:
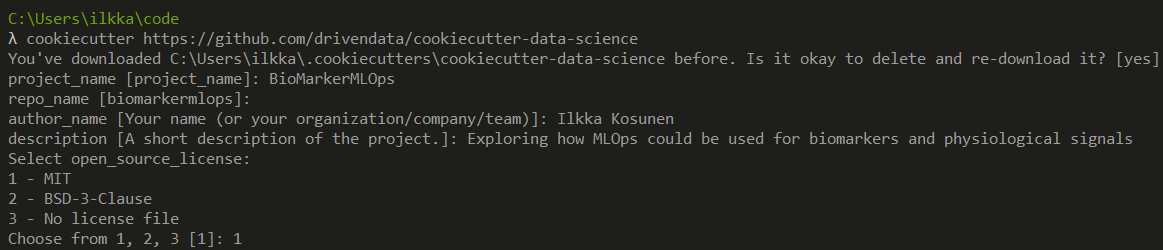
However, the basic template has things I’m not going to use for personal preference, like anaconda, pythonenv and Makefile, which I clean up. While I think I’ll at some point move to pythonenv, for now I find it much easier just having the venv in the same dir where for example VS Code can easily find it, and making containers having the dependencies there somehow feels easier for me, but yeah, probably not the best pattern.
Also, I probably should update this into my work-in-progress Github MLOps template that is now based on Microsoft’s one.
Get Organizized via Github Projects
After using Azure Boards in work I try to learn here also the to tools provided by github, namely Projects and Actions.