K8 studies start !
2022-02-13 17:59:33
Reading the Kubernetes book by Nigel Poulton. I’ve also have it as an audiobook from Audible, simply to reinforce the concepts using multiple sensory modalities.
To kickstart my Sunday study, I took some usual acetyl-l-carnitine, but in addition to that, today I also took my fish oil early so that I can try out the “daily nootropic capsules” I bought from Bulk that have instructions to be taken with food. So, fish oil and some flaxseed will have to do for “Food”. And of course there is a need for proper study music: today decided to go with Worakls. Anyways, back to k8!
Kubernetes in a Month of Lunches 2022-08-06 10:01:59
Day 1
I can find the containers with docker but if I rm them, kubernetes will restart them
docker container ls -q --filter label=io.kubernetes.container.name=hello-kiamol
docker container rm -f $(docker container ls -q --filter label=io.kubernetes.container.name=hello-kiamol)
to get access to a pod:
kubectl port-forward pod/hello-kiamol 8080:80
Deployments
kubectl get deploy hello-kiamol-2 -o jsonpath='{.spec.template.metadata.labels}'
Deployments use a template to create Pods, and part of that template is a metadata field, which includes the labels for the Pod(s). Querying Pods that have a matching label:
kubectl get pods -l app=hello-kiamol-2
Resouces can have labels applied at creation and then addded, removed, or edited during their life-time. Controllers use a label selector to identify the resources they manage. This process is flexible because it means controllers don’t need to maintain a list of all the resources they manage; the label selector is part of the controller specification, and controllers can find matching resources at any time by querying the Kubernetes API.
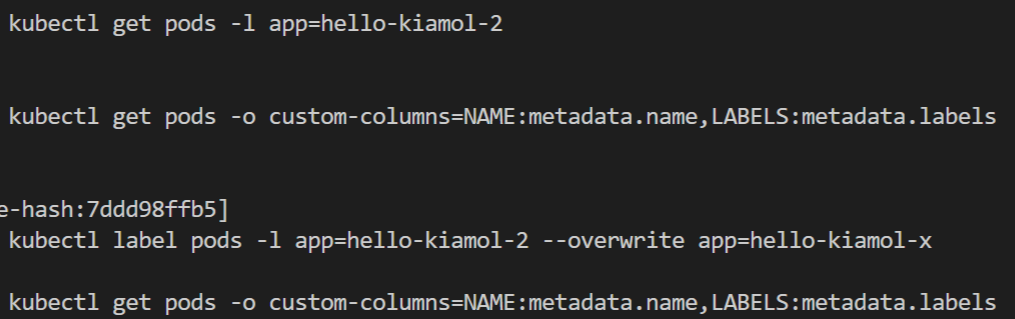
When you relabel a Pod the deployment creates a new one so you end up with two

Defining deployments in application manifests
# Manifests always specify the version of the Kubernetes API
# and the type of resource
apiversion: v1
kind: Pod
# Medata for the resource includes the name (mandatory)
# and the labels (optional)
metadata:
name: hello-kiamol-3
# The spec is the actual specification for the resource
# For a Pod the minimum is the container(s) to run,
# with the container name and image.
spec:
containers:
- name: web
image: kiamol/ch-02-hello-kiamol
We can still connect to the containers maintained by k8s:
kubectl exec -it hello-kiamol -- sh
Copying files from container:
kubectl cp hello-kiamol:/usr/share/nginx/html/index.html /tmp/kiamol/ch02/index.html
Day 3
The link between the Service and its Pods is setup with a label selector, just like the link between Deployment and Pods.
The default type of Service in Kubernetes is called ClusterIP. It creates a clusterwide IP address that Pods on any node can access. The IP address works only within the cluster.
Routing external traffic to pods
LoadBalancer is a simple and flexible approach.
apiVersion: v1
kind: Service
metadata:
name: numbers-web
spec:
ports:
- port: 8080
targetPort: 80
selector:
app: numbers-web
type: LoadBalancer
LoadBalancer works differently on different k8s systems: on docker desktop it always maps to localhost.
Day 4 ConfigMaps and Secrets
ConfigMaps and Secrets can be created with kubectl like other objects, but they are static objects.
ConfigMag is just a resource that stores some data that can be loaded into a Pod.
K8s has the following app configuration approach:
- Default app settings are baked into the container image.
- The actual settings for each environment are stored in a ConfigMap and surfaced into the container filesystem.
- Any settings that need to be tweaked ca be applied as environment variables in the Pod specification for the Deployment.
Surfacing configuration data from ConfigMaps
The alternative to loading configurations items into environment variables is to present them as files inside directories. The container filesystem is a virtual construct, built from the container image and other sources. K8s can use ConfigMaps as a filesystem source - they are mounted as a directory, with a file for each item.
K8s manages this strange magic with two features of the Pod spec: volumes, which make the contents of the ConfigMap available to the Pod, and volume mounts which load the contents of the ConfigMap volume into a specified path in the Pod container.
spec:
containers:
- name: web
image: kiamol/ch04-todo-list
volumeMounts: # Mount a volume into the container
- name: config # names the volume
mountPath: "/app/config" # dir in container
readOnly: True
volumes:
- name: config
configMap:
name: todo-web-config-dev
Secrets
Secrets have similar API to ConfigMaps but are handled differently: Secrets are sent only to nodes that need to use them and are stored in memory rather than on disk. K8s also supports encryption both rest / transit.
Day 5 : volumes
You can use EmptyDir volumes for any applications that use the filesystem for temporary storage. EmptyDir shares the lifecycle of the Pod, not the container.
spec:
containers:
- name: sleep
image: kiamol/ch03-sleep
volumeMounts:
-name: data
mountPath: /data
volumes:
- name: data
emptyDir: {}
Host Path
The next level of durability comes from using a volume thah maps to a directory on the node’s disk, which Kubernetes calls a HostPath Volume. When ther container writes data into the mount directory, it actually is written to the disk on the node.
This works well on single node installations of K8s but have to be careful if multiple nodes are involved.
Persist!
Pods are an abstraction over the compute layer, Services are an abstraction over the network layer. The storage layer abstractions are PersistentVolume and PersistenVolumeClaim.
A PersistentVolume is a Kubernetes object that defines an available piece of storage.
Here selecting specific node via label which is not necessary if using distributed filesystem:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv01
spec:
capacity:
storage: 50Mi
accessModes:
- ReadWriteOnce
local:
path: /volumes/pv01
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kiamol
operator: In
values:
- ch05
Pods can’t use that PV directly; instead, they need to claim it using a PersistentVolumeClaim(PVC). The PVC is the storage abstraction that Pods use, and it just requests some storage for an application. The PVC gets matched to a PV by Kubernetes and it leaves the underlying volume details to the PV.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 40Mi
storageClassName: ""
The PVC spec includes an access mode, storage amount, and storage class. If no storage class is specified, Kubernetes tries to find an existing PV that matches the requirements in the claim. If there is a match, then the PVC is bound to the PV - there is a one-to-one link, so once a PV is claimed, it is not available for any other PVCs to use.
This is a static provisioning approach, where the PV needs to be explicitly created so Kubernetes can bind to it. If there is no matching PV when you create a PVC, the claim is still created, but it’s not usable. It will stay in the system waiting for a PV to be created that meets its requirements.
Dynamic Provisioning
So far we’ve used a static provisioning workflow. We explicitly created the PV and then created the PVC, which Kubernetes bound to the PV. That works for all Kubernetes clusters and might be the preferred workflow in organizations where access to storage is strictly controlled, but most Kubernetes platforms support a simpler alternative with dynamic provisioning.
In dynamic provisioning workflow, you just create the PVC, and the PV that backs it is created on demand by the cluster.
Day 6 Controllers
You’ll use a Deployment to describe your app in most cases; the Deployment is a controller that manages ReplicaSets, and the ReplicaSet is a controller that manages Pods.
The YAML for a ReplicaSet is almost the same as for a Deployment; it needs a selector to find the resources it owns and a Pod template to create resources. There is additional field, replicas, that defines how many pods to run.
DaemonSet
The DaemonSet runs a single replicat of a Pod on every node in the (or subset of nodes with selector.)